Am Sylvia Lawry Centre for Multiple Sclerosis Research (SLCMSR) an der Technischen Universität
München wird anhand einer weltweit einmaligen Datensammlung von klinischen Studien und Registerdaten
zur Multiplen Sklerose ein neuer Ansatz in der Therapieforschung begangen. Ein wesentliches Ziel des
Zentrums ist die Entwicklung von ``virtuellen Placebo-Patienten``, die es gestatten, die Wirksamkeit
neuer Medikamente ohne echte Placebogruppen nachzuweisen. Die virtuellen Placebo-Gruppen müssen mit
Hilfe statistischer Methoden aus der Datensammlung errechnet werden. Danach sollen die Daten der verschiedenen
Placebo-Gruppen analysiert und visualisiert werden.
Das Sylvia Lawry Centre setzt Macromedia ColdFusion als Web-Application Server ein [DEVCF], der in der neuen Version
MX auch J2EE kompatibel ist. Durch die Integration
der Flash-Technologie wurde gleichzeitig eine umfangreiche Graphikbibliothek geschaffen, mit der schnell
Charts realisiert werden.
Mit dieser Technologie wird das Centre der Öffentlichkeit und den weltweit verteilten Experten des
wissenschaftlichen Beirats aktuelle Einblicke in die weltweit größte Datenbank zu Multiplen Sklerose
(MS) Studien geben. Die Daten sollen dabei nicht ``roh``, sondern in Form von statistischen
Visualisierungen dargestellt und über ein Web-Interface zugänglich gemacht werden. Dabei sollen die
Daten zum Zeitpunkt des Zugriffs aus der Datenbank abgerufen, vorverarbeitet und aggregiert werden.
Diese Daten müssen dann automatisiert in Form interaktiver Visualisierungstools dargestellt werden.
Die Aufgabe dieses Fortgeschrittenen-Praktikums besteht darin, eine Bibliothek von webbasierten Tools
zur Datenaggregation und -vorverarbeitung, sowie zur intelligenten, automatisierten und interaktiven Visualisierung
von grundlegenden Datenstrukturen, deskriptiven Statistiken und Drill-Down-Objekten auf
dem Web-Application Server ColdFusion MX entwickeln.
Diese Bibliothek soll folgende Aufgaben lösen:
Innerhalb der Ausarbeitung zum Fortgeschrittenen-Praktikum wird anfangs die Anforderungsanalyse
beschrieben, es folgt eine kurze Beschreibung einiger
statistischerBegriffe, die für das Praktikum relevant sind. Anschließend folgt eine Beschreibung
der Architektur von ColdFusion MX. In Kapitel 5 folgt die Beschreibung des Entwurfs und der
Funktionalitäten der Bibliothek.
Wie bereits in der Einleitung geschildert, besteht die Aufgabe dieses Fortge-
schrittenen-Praktikums in der
Entwicklung einer Bibliothek von webbasierten Tools, mit deren Hilfe Daten in einer statistisch
adäquaten Form visualisiert werden können.
Damit die in den Daten enthaltene Information übersichtlich und graphisch richtig dargestellt wird,
benutzt man die deskriptive Statistik [WC99]. Die deskriptive Statistik hat die Aufgabe, empirisch gewonnene
Daten zu ordnen, durch bestimmte Maßzahlen zusammenzufassen und graphisch oder tabellarisch
darzustellen. Der Benutzer erhält als Output die graphische Darstellung der Daten.
Alle Berechnungen, Datenvorverarbeitungen und Aggregationen sollen im Hintergrund transperent für den Benutzer
ablaufen.
Die Programm-Bibliothek soll über die im folgenden beschriebenen Funktionalitäten verfügen.
Es kann passieren, dass die Daten in der Datenbank
bereinigt werden müssen. Der Grund dafür kann sein, dass es fehlerhafte Daten gibt (falsch getippte
Daten), Daten mit fehlenden Werten (Datenbankfelder mit nicht eingegebenem Wert), Daten mit nicht
passendem Datentyp. Diese Daten müssen erkannt und entfernt werden. Da im konkreten Anwendungsfall
eine "´saubere"´ Datenbank zur Verfügung steht, reduziert sich hier der Aufwand. Relevant bleibt
u.a. der Umgang mit fehlenden Werten.
Eine weitere wichtige Funktionalität der Bibliothek soll die Datenanalyse sein. Zu der Datenanalyse
gehört auch die Festlegung des Datentyps, der für die spätere Visualisierung der Daten wichtig ist.
Wenn es sich z.B. um Textdaten handelt, dann impliziert das, dass die Daten qualitativ (kategorial)
sind und dass sie mit Hilfe eines Diagramms mit festen Kategorien dargestellt werden.
Ein weiterer wichtiger Punkt bei der Datenanalyse ist die Erkennung der Verteilungsmuster.
Es sollte schon vor der Datenvisualisierung klar sein, ob es sich um eine symmetrische (z.B. Normalverteilung),
eine rechtsschiefe oder eine linksschiefe Verteilung handelt. Zur Datenanalyse gehört auch die
Berechnung verschiedener statistischer Größen, wie Median, Mittelwert, Quantile oder
Regressionsparameter, die unterschiedlich gut für unterschiedliche Verteilungstypen geeignet sind.
Dabei sollen alle genannten statistischen Größen berechnet werden und bei Bedarf wird die
geeignetste Größe benutzt.
Die Daten sollen bei Bedarf sinnvoll in Klassen (Kategorien) eingeteilt werden. Diese Einteilung hängt wieder vom
Datentyp ab. Wenn die Daten aus stetigen Messgrößen bestehen, können die Daten klassifiziert werden. Dazu teilt man
den gesamten Wertebereich der Daten in Intervalle ein, die Klassen genannt werden. Die Breite der
einzelnen Klassen ist gleich. Ziel der Klassifizierung ist es, einerseits die tabellarische und
graphische Darstellung übersichtlicher zu gestalten, ohne andererseits zuviel an Information zu
verlieren. Bei qualitativen Daten sind die Klassen durch die Datenausprägungen vorgegeben.
Eine zentralle Aufgabe besteht in der Aufbereitung der Daten in eine Form, die von der ColdFusion Funktion
CHCHART, die für das Zeichnen von Diagrammen in ColdFusion zuständig ist, nicht fehlinterpretiert
werden. Zum Beispiel unterscheiden die graphischen Funktionen von ColdFusion keine diskreten Daten. Dabei kann es
sehr leicht zu falscher Visualisierung der Daten kommen (siehe Abb. 4.3).
Der letzte Punkt der Anforderungen ist die Implementierung einer graphischen Benutzeroberfläche.
Die Benutzeroberfläche muss leicht bedienbar sein. Der Benutzer muss auf einen Blick alle in der
Datenbank vorhandenen Attribute sehen. Von diesen Daten kann er auswählen, welche er visualisieren
möchte. Zur Visualisierung der Daten wurden im Rahmen des Fortgeschrittenen Praktikums
prototypisch zwei Typen von Diagrammen implementiert:
das Histogramm und der Scatter-Plot. Beim Histogramm sollen zusätzliche Funktionalitäten wie
Achsenskalierung, Drill-Down Funktionalität (per linken Mausklick auf einen Histogrammbalken gelangt
man zum Histogramm der ausgewählten Klasse), Änderung der Klassenanzahl und Anzeigen des Konfidenzintervalls
implementiert werden. Beim Scatter-Plot sollen zusätzlich die Regressionsgerade
und den Konfidenzbereich dargestellt werden.
Der Gegenstand einer Untersuchung, die Beobachtungseinheit (Patient, Organ usw.), ist durch eine Reihe von Eigenschaften
oder Variablen, die Merkmale, gekennzeichnet [FH99]. Diese können verschiedene Eigenschaften oder Zahlenwerte, die Ausprägungen,
annehmen. Die ermittelten Ausprägungen der Merkmale sind die Daten.
Man unterscheidet qualitative und quantitative Merkmale.
Qualitative Merkmale sind jene, die primär nicht durch Zahlenangaben erfassbar sind (typische Beispiele: Geschlecht, Blutgruppe).
Quantitative Merkmale sind durch Zahlenwerte erfassbar und angebbar (Körpergröße, Gewicht).
Sei A ein qualitatives Merkmal mit den Ausprägungen .
In einer Stichprobe vom Umfang habe man die Ausprägung mit der absoluten Häufigkeit beobachtet
(). Bei Beobachtungseinheiten aus der Stichprobe fehle die Angabe zum Merkmal . Dann ist offenbar
Unter den relativen Häufigkeiten, genauer den adjustierten relativen Häufigkeiten, versteht man
Der Zusatz ``adjustiert`` soll betonen, dass man bei der Berechnung nur diejenigen Beobachtungseinheiten berücksichtigt,
bei denen die Angaben zum Merkmal tatsächlich vorliegen. Meist werden die relativen Häufigkeiten in Prozent angegeben:
Der arithmetische Mittelwert ist die am häufigsten gebrauchte Lagemaßzahl. Man erhält sie als durchschnittlichen Wert,
indem man alle Werte
addiert und durch die Gesamtzahl der Daten dividiert:
Zur Berechnung des empirischen Medians müssen die Daten der Größe nach geordnet werden,
d. h. man geht von der Urliste der Daten
zur Rangliste
über, indem man
die Daten der Größe nach ordnet, heißt Rangzahl. Die Rangzahl gibt den Platz auf der Rangliste an.
ist die Rangzahl des kleinsten Wertes, ist die Rangzahl des größten Wertes. Der empirische Median ist der
Wert ``in der Mitte`` der Rangliste, d. h. die Hälfte der Messwerte sind kleiner bzw. größer als der Median.
Die Ermittlung der funktionalen Abhängigkeit verschiedener Variablen nennt man Regression. Bei der linearen Regression von
auf geht man davon aus, dass zwischen den beiden Merkmalen ein linearer Zusammenhang der Form
besteht. Die Abweichung der tatsächlich festgestellten Wertepaare von der durch die Gleichung beschriebenen Geraden
führt man auf den Einfluss nicht erfasster Störgrößen zurück. Es stellt sich die Aufgabe, und
vernünftig aus den Daten zu schätzen.
Dieses Problem wurde mathematisch von C. F. Gauß (Methode der kleinsten Quadrate) gelöst. Man erhält die Schätzwerte bzw. ,
die aus den Daten mithilfe der Formeln
bzw.
berechnet werden.
Die Gerade
heißt (empirische) Regressionsgerade der Regression von auf ;
, der Anstieg der Regressionsgeraden, heißt (empirischer) Regressionskoeffizient.
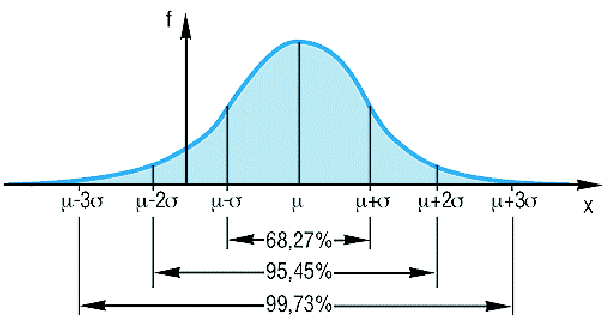
Eine stetige Zufallsvariable heißt mit Erwartungswert und Varianz
normalverteilt, wenn die Wahrscheinlichkeit dafür, dass höchstens gleich ist,
durch das Integral der Gaußschen Fehlerfunktion gegeben ist, in Formeln:
Hierfür schreibt man abkürzend
.
ist die Verteilungsfunktion der Normalverteilung.
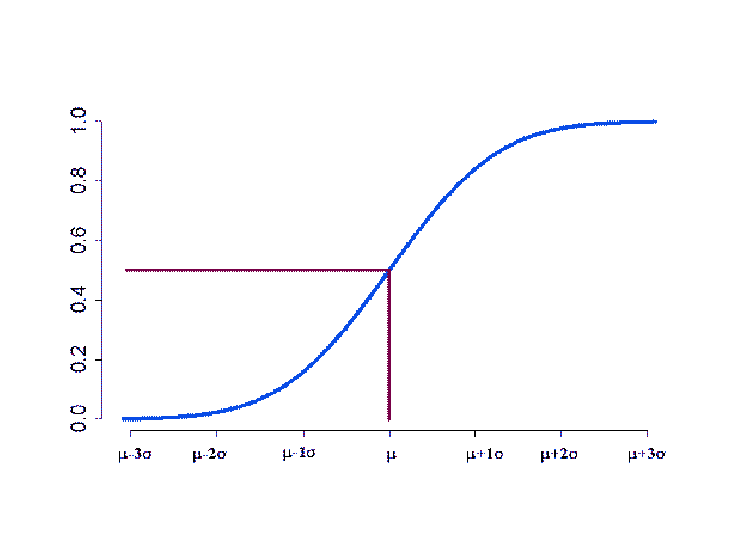
Deren erste Ableitung
ist die Dichtefunktion der Normalverteilung. Das Bild der Dichtefunktion ist die bekannte Glockenkurve (Abbildung 3.1).
Abbildung 3.1:
Dichtefunktion der Normalverteilung
Die Verteilungsfunktion der Normalverteilung hat einen sigmoiden (s-förmigen) Kurvenverlauf (Abbildung 3.2).
Abbildung 3.2:
Verteilungsfunktion der Normalverteilung
Der unbekannte Erwartungswert einer Normalverteilung
wird durch den Mittelwert aus einer zufälligen Stichprobe geschätzt. Zu dem Mittelwert
lässt sich ein Intervall, das sogenannte Konfidenzintervall, angeben, das den unbekannten Erwartungswert
mit einer vorgegebenen Konfidenzwahrscheinlichkeit enthält. Die Intervallgrenzen
bzw. berechnet man aus den Formeln
Dabei ist die Standardabweichung der betrachteten Normalverteilung. ist der Stichprobenumfang und
das
-Quantil der Standardnormalverteilung.
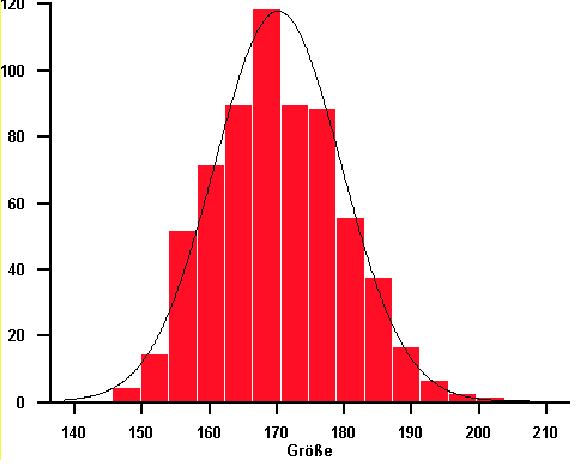
Das Histogramm dient zur graphischen Darstellung für die Häufigkeitsverteilung quantitativer Merkmale (Abbildung 3.3).
Die Daten werden der Größe nach in Klassen eingeteilt und diese auf einer Grundlinie aufgetragen. Über jeder Klasse wird
ein Rechteck gezeichnet, dessen Flächeninhalt proportional zur relativen Häufigkeit der auf die Klasse entfallenden
Elemente ist. Ist die Anzahl der Daten groß genug und bei stetigen Merkmalen die Klassenbreite klein genug, so entspricht
die Form des Histogramms der Dichtefunktion für die stetige Zufallsvariablen bzw. der Wahrscheinlichkeitsfunktion
für diskrete Zufallsvariablen.
Abbildung 3.3:
Histogramm mit Normalverteilungsdichte des Merkmals ``Größe``
Das Histogramm selbst ist nicht fest definiert, so daß eine Aufgabe darin besteht, variable Parameter (wie z.B.
Anzahl der Balken, Skalierung der x-Achse) für den Benutzer einfach veränderbar zu gestalten.
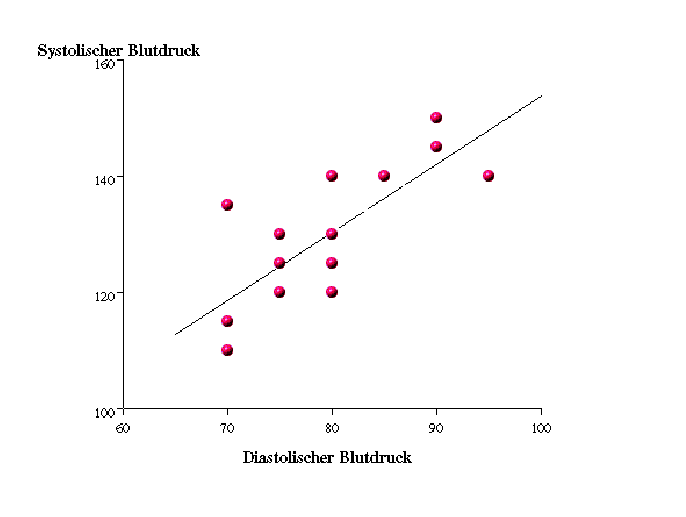
Die Punktwolke dient zur graphischen Veranschaulichung des Zusammenhangs zweier stetiger Merkmale, die an
Beobachtungseinheiten erfasst wurden. Jede Beobachtungseinheit liefert genau einen Punkt für die Punktwolke.
Der Zusammenhang zwischen zwei Merkmale wird mit der Hilfe der Regression untersucht (Abbildung 3.4).
Mit der linearen Regression wird z.B. versucht diejenige Gerade zu bestimmen, welche den kleinsten Abstand zu den Punkten hat,
d.h. die Lage der Punkte soll so genau wie möglich durch eine lineare Funktion (Gerade) beschrieben werden.
Bei ColdFusion MX handelt sich um die derzeit neueste Version des Macromedia ColdFusion Servers, die zu Beginn des
Praktikums noch als Beta-Version unter dem Code-Namen NEO vorlag. In
diesem Kapitel werden einige grundsätzliche Merkmale der Architektur von ColdFusion genannt, sowie
eine kurze Beschreibung der graphischen Funktionen gegeben, die für dieses Praktikum von
großer Bedeutung sind.
Durch eingängige Skripterstellungsfunktionen, Möglichkeiten zur Verbindung mit
Unternehmensdaten und integrierten Such- und Diagrammerstellungsfunktionen
können Entwickler mit ColdFusion MX dynamische Webseiten,
Content-Publishing-Systeme, E-Commerce-Seiten und anderes bereitstellen.
Dem ColdFusion MX Server liegt ein auf der JRUN-Technologie basierender J2EE-Server zugrunde [NEO].
ColdFusion MX kann sowohl als Stand-alone-Server eingesetzt werden, als auch mit Java Application Servern,
wie dem IBM WebSphere Application Server oder auch Servern von Sun iPlanet, zusammenarbeiten.
Die ColdFusion MX-Umgebung unterstützt die Betriebssysteme Windows, Linux und Unix, kann
Internetstandards und Komponentenmodelle integrieren, wie XML, Webdienste, Java, .NET/COM und COBRA.
ColdFusion Anwendungen bestehen aus einer Ansammlung von Templates oder Seiten,
die die ColdFusion Markup Sprache (CFML) verwenden [CFREF]. CFML ist eine leicht zu erlernende Sprache, die
mehr als 75 Tags sowie mehr als 240 eingebaute Funktionen umfasst. Die Syntax von ColdFusion ähnelt
der von HTML und XML. Es werden wieder Tags verwendet, um Daten zu verarbeiten. ColdFusion erlaubt
auch den Entwicklern, die Sprachumgebung zu erweitern, indem sie ihre eigene Custom Tags oder
benutzerdefinierte Funktionen (UDF) entwickeln oder COM, C++ und Java Komponenten integrieren.
Neu in ColdFusion MX sind auch die ColdFusion Komponenten (CFC). Die CFC's sind wiederverwendbare Anwendungskomponenten,
die von den ColdFusion Seiten abgerufen werden. Sie werden benutzt, um die Web-Anwendungen auf eine objektbasierte Weise zu
organisieren.
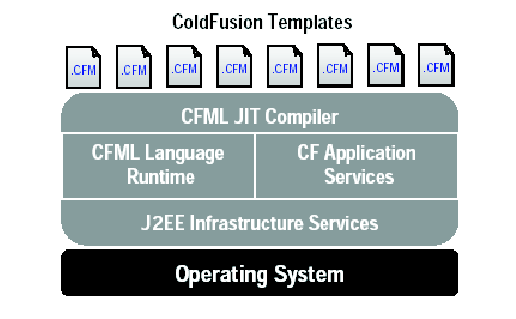
ColdFusion MX ist J2EE kompatibel. Er baut dabei auf einer neuen
Architektur auf, die die Verlässlichkeit und Skalierbarkeit der Java-Plattform übernimmt, jedoch
nicht deren Komplexität.
Abbildung 4.1:
Die Architektur von dem ColdFusion MX Server
ColdFusion MX besteht aus vier Subsystemen (Abbildung 4.1):
Die Infrastrukturdienstleistungen, die mit
ColdFusion MX kommen, werden durch eine eingebettete Version von Macromedia JRun zur Verfügung
gestellt. Die J2EE Engine in JRun entspricht dem J2EE Standard. Die Infrastrukturdienstleistungen
umfassen die Datenbankanbindungen, die Sicherheitsdienste, das Interagieren mit dem Betriebssystem und
das Steuern der HTTP, FTP und POP Protokolle.
Anstatt p-Code (preprocessed Code),
wie in den früheren Versionen von ColdFusion, erzeugt der CFML JIT Compiler in ColdFusion MX Java Bytecode.
Fordert der ColdFusion Server ein ColdFusion Template zum ersten Mal an, wird dieses Template
von dem CFML JIT Compiler in Java Bytecode übersetzt und im Cache gespeichert. Dieser Code
wird dann auf dem Server von der CFML Language Runtime ausgeführt. Im Template enthaltenen
Instruktionen wie Datenbankanfragen oder Formatierungen werden auch von dem CFML Language Runtime
durchgeführt.
Der CFML Language Runtime umfasst die Verarbeitung aller ColdFusion Tags und Funktionen.
Der Language Runtime bearbeitet auch die Interaktionen mit den Application Services, wie z.B. Charting und Graphing
oder Ganztextsuche.
Die Fähigkeit, Daten in einem Diagramm anzuzeigen, kann die Dateninterpretation enorm vereinfachen.
Anstelle einer einfachen Tabelle mit numerischen Daten werden die Daten anhand von
Bar-Charts, Pie-Charts, Linien oder anderen Diagrammarten mit Farben, Untertiteln, mit zwei- oder
dreidimensionaler Darstellung visualisiert. Der cfchart Tag zusammen mit cfchartseries
und cfchartdata liefern viele unterschiedliche Diagrammarten. Mittels der Tagattribute lassen sich die Diagramme
individuell anpassen.
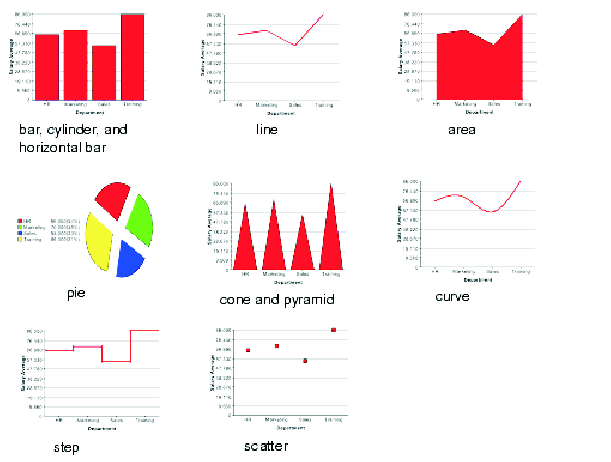
ColdFusion unterstützt 11 verschiedene Arten von Diagrammen in zwei oder drei Dimensionen.
Die folgende Abbildung 4.2 zeigt ein zweidimensionales Beispiel aller Diagrammarten.
(Bemerkung: Im zweidimensionalen Fall erscheinen das Bar und das Zylinder Diagramm gleich,
sowie der Konus und die Pyramide.)
Um ein Diagramm zu erstellen, wird der cfchart Tag zusammen mit mindestens einem
cfchartseries Tag eingesetzt, der wiederum einen oder mehrere cfchartdata Tags umfassen kann.
cfchart:
Spezifiziert den Container, in dem das Diagramm erscheint. Dieser Container definiert die Höhe,
Breite, Hintergrundfarbe, Beschriftung und andere Eigenschaften des Diagramms. Jeder cfchart
Tag beinhaltet mindestens einem chchartseries Tag
cfchartseries:
Spezifiziert eine Datenbankanfrage, die die Daten an das Diagramm liefert und/oder einen oder
mehrere cfchartdata Tags, die einzelne Datenpunkte spezifizieren. Spezifiziert die
Diagrammart, die Farben für das Diagramm und andere optionale Attribute
cfchartdata:
Spezifiziert optional einzelne Datenpunkte für den cfchartseries Tag
Der folgende Code zeigt einen Ausschnitt aus dem Programmcode des Fortgeschrittenen-Praktikums,
wie man ein Histogramm erstellen kann:
#Height#, #width#,#attributes.beispiel#, #attributes.ylabel#,
#d_d_blau# und #gruen# sind vordefinierte globale Variablen.
#array_items_histogrammm[j]#
und #array_values_histogrammm[j]#
sind Arrays mit den Punkten für die X-Achse und deren Werte.
Für Datenbankanfragen wird der Tag cfquery benutzt. Er spezifiziert unteranderem
den Anfragennamen, die Datenquelle, und ob die Anfrage gecacht werden soll. In dem cfquery
Tag sind SQL Anweisungen eingeschlossen, mit denen die Datenbankanfrage spezifiziert wird. Die entsprechende
Datenbankanfrage für den obigen Code sieht folgendermaßen aus:
<cfquery name="´all_datasets"´ datasource="´#dsn#"´ cachedwithin="´#CreateTimeSpan(0,1,0,1)#"´> SELECT #column# FROM #table# WHERE (#colum# is not null) </cfquery>
#dsn#, #column# und #table# sind wieder vordefinierte globale Variablen.
Wenn man die bereitstehenden Funktionen von ColdFusion MX für Visualisierung von Daten benutzt,
merkt man sehr schnell, dass die graphische Darstellung für viele Fälle nicht sehr adäquat ist.
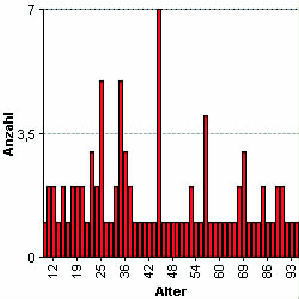
Z.B in Abbildung 4.3 ist das Problem der nicht äquidistanten Skalierung der X-Achse vor allem im
Bereich zwischen 70 und 80 leicht zu erkennen.
Abbildung 4.3:
In dieser Form unbrauchbare Standardausgabe einer kontinuirlichen Datenreihe von Alterswerten
mit ColdFusion MX
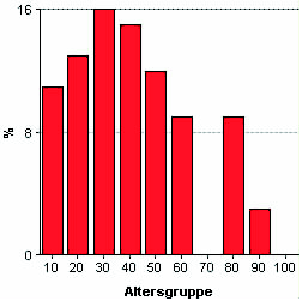
Um ein Histogramm zu erstellen, das z.B. die
Datengruppierung nach dem Alter und auch noch den Prozentanteil jeder Altersgruppe darstellt
(siehe Abb. 4.4), ist eine manuelle Vorverarbeitung der Daten erforderlich. Deshalb wäre hier ein Tool
sehr hilfreich, das dies automatisiert und mächtige analytische Werkzeuge zur Datenuntersuchung
und Datenanalyse liefert. Das genau ist das Ziel dieses Fortgeschrittenen Praktikums.
Abbildung 4.4:
Sinnvolles Histogramm über die Altersverteilung- hier per Hand aus den Daten von Abb. 4.3 erstellt.
In diesem Kapitel werden die verschiedene Komponenten der Bibliothek, die im Rahmen des
Fortgeschrittenen-Praktikums implementiert worden sind, und deren Funktionalitäten beschrieben.
Die Bibliothek besteht aus ColdFusion Templates (CFML-Dateien) und ColdFusion Komponenten (CFC).
Die Komponenten sind erweiterbare und ersetzbare Bestandteile der Bibliothek, die die
Anforderungen an die Bibliothek aus Kapitel 2 erfüllen, wie die Vorverarbeitung der Daten,
Aufbereitung der Daten für Visualisierung und das Berechnen verschiedener statistischer Größen.
Sie enthalten eine oder mehrere Methoden, die in den Templates aufgerufen werden. In den ColdFusion
Templates werden die von den Komponenten vorbereitenden Daten visualisiert.
Zentrale Rolle in der Bibliothek spielt die Datei index.cfm. Sie holt sich alle verfügbare Attribute aus der
Datenbank und stellt diese Variablen dem Benutzer zur Auswahl zur Verfügung. Wenn der Benutzer ausgewählt hat,
welche Daten visualisiert werden sollen, übergibt die Datei index.cfm die ausgewählten
Daten dem Template datentest.cfm. Das Template prüft den Datentyp und von dem Datentyp abhängend
ruft es das entsprechende ColdFusion Template auf. Das Template ruft die ColdFusion Komponente mit
ihrer Methode auf und übergibt ihr die notwendigen Parameter, wie Datenbanktabelle, Datenbankattribut
und andere. Die ColdFusion Komponente gibt die Ergebnisse ihrer Methoden dem ColdFusion
Template zurück und dieses visualisiert die Daten mit Hilfe der graphischen Funktionen von ColdFusion. Das
Template ruft nachher wieder die Datei index.cfm auf.
Z.B. der Benutzer wählt das Datenbankattribut "´Age of First Visit"´ (siehe Abb. 5.10).
Das Template index.cfm ruft das Template datentest.cfm, das den Datentyp prüft, stellt fest,
dass es sich um einen numerischen Datentyp handelt, und damit um eine quantitative Variable,
und ruft das Template histogramm.cfm, das von seiner Seite die Komponente histogramm.cfc ruft.
Die Aufgabe der Komponente ist im Kapitel 5.1, Punkt 4 beschrieben.
Die folgenden Diagramme zeigen den Zusammenhang zwischen den einzelnen ColdFusion Komponenten
und Templates (siehe Abb. 5.1) und ein UML Aktivitätsdiagramm der Bibliothek (siehe Abb.5.2).
Abbildung 5.1:
Zusammenhang zwischen den einzelnen Komponenten in der Bibliothek
Abbildung 5.2:
UML Aktivitätsdiagramm der Bibliothek
Wenn die Bibliothek gefordert ist, bestimmte Daten zu visualisieren, werden die Daten zuerst
einer Datentypprüfung unterzogen. Es wird zwischen textuellen, numerischen und booleschen Daten unterschieden.
Von dem Datentyp wird weiter bestimmt, ob die Daten qualitativ oder quantitativ sind und anhand dieser Information werden die
entsprechenden ColdFusion Templates und Komponenten aufgerufen.
Zur besseren Erläuterung der Funktionalitäten der Bibliothek folgt eine kurze Beschreibung der
verschiedenen Komponenten (CFCs) und Templates (CFML-Dateien). Es wird zwischen sechs verschiedenen Fällen unterschieden:
Darstellung qualitativer Daten (z.B. Geschlecht):
Diese Daten werden von der ColdFusion Komponente histogramm_feste_kategorien.cfc bearbeitet.
Die Komponente besteht aus einer Methode freq, die als Input den Datenbanknamen,
die Datenbanktabelle, das Datenbankattribut, den Datentyp und einen Selektor (ob alle Datensätze oder
nur ein bestimmter Teil von ihnen bearbeitet werden muß) bekommt. Die Komponente führt die Datenbankanfrage durch,
gruppiert die Daten in Klassen (die Klassen sind von allen Datenausprägungen gebildet), berechnet die Summe der Datensätze für jede Klasse und übergibt die Ergebnisse
ihrer Berechnungen dem Template histogramm_feste_ kategorien.cfm, das die Daten mit Hilfe
der ColdFusion Funktion chchart in Form eines Balkendiagramms darstellt (Abbildung 5.3).
Abbildung 5.3:
Qualitative Daten (Geschlecht)
Darstellung des Zusammenhangs zwischen qualitativen und qualitativen Daten (z.B. zwischen Verlauf der Krankheit und Geschlecht):
wird von der ColdFusion Komponente histogramm_prozent_feste_ ketegorien.cfc bearbeitet.
Die Eingabeparameter sind wie in Punkt 1, zusätzlicher Parameter ist nur ein zweites
Datenbankattribut. Die Komponente gruppiert die Daten des ersten Datenbankattributs in Klassen,
für jede Klasse berechnet sie den prozentuellen Anteil der Daten des zweiten Datenbankattributs
und übergibt die Ergebnisse dem Template histogramm_prozent_feste_kategorien.cfm, das die
Daten graphisch als gestapeltes Balkendiagramm darstellt (Abbildung 5.4).
Abbildung 5.4:
Zusammenhang zwischen qualitativen und quantitativen Daten (zwischen Verlauf der Krankheit und Geschlecht)
Darstellung des Zusammenhangs zwischen qualitativen und booleschen Daten (z.B. zwischen Geschlecht und Enhancement):
wird von der Komponente histogramm_feste_kategorien_0_1.cfc bearbeitet. Die Komponente hat die
selben Aufgaben wie die Komponente in Punkt 2, nur das zweite Datenbankattribut ist eine
0/1 Variable. Zusätzlich wird auch die Variabilität in den Messungen als Konfidenzintervall
berechnet und dargestellt. Die Daten werden von dem Template histogramm_feste_kategorien_0_1.cfm als
Balkendiagramm visualisiert (Abbildung 5.5).
Abbildung 5.5:
Zusammenhang zwischen qualitativen und booleschen Daten (zwischen Geschlecht und Enhancement)
Quantitative Daten (z.B. Alter):
Bei den quantitativen Daten sind mehr Funktionalitäten möglich als bei den qualitativen.
Die erste Funktionalität ist die benutzergesteuerte Klassenbildung. Der Benutzer gibt dabei die Anzahl der Balken
für das Histogramm vor. Die Daten werden von der ColdFusion Komponente histogramm.cfc
bearbeitet. Die Komponente besteht aus einer Methode group, die als Input den
Datenbanknamen, die Datenbanktabelle, das Datenbankattribut, den Datentyp, einen Selektor
und die gewünschte Anzahl der Klassen bekommt.
Die Komponente bildet die Klassen, berechnet die Summe der Datensätze für jede Klasse und
übergibt die Ergebnisse ihrer Berechnungen dem Template histogramm.cfm, das die Daten
mit Hilfe der ColdFusion Funktion cfchart in Form eines Histogramms darstellt (Abbildung 5.6).
Abbildung 5.6:
Quantitative Daten (Alter)
Andere mögliche Funktionalität ist die Skalierung der X-Achse.
Das ist Aufgabe der Komponente histogramm_skal.cfc. Diese bekommt als Eingabe die selben
Parameter wie die Komponente histogramm.cfc, zusätzliche Parameter sind die
Skalierungsparameter "´Von"´, "´Bis"´ und "´Schrittweite"´. Von den benutzerdefinierten Skalierungsparameter berechnet die
Komponente die Anzahl der Klassen und ihre Größe. Die Darstellung ist Aufgabe des Templates
histogramm_skal.cfm, die Daten sind als Histogramm dargestellt (Abbildung 5.7).
Abbildung 5.7:
Skalierung der X-Achse bei quantitativen Daten
Die letzte Funktionalität ist die Drill-Down-Funktionalität. Per linken Mausklick auf einem
Balken gelangt der Benutzer in das Histogramm der gewünschten Gruppe. Diese Aufgabe wird von der
Komponente histogramm_drill_down.cfc erfüllt.
Z.B. klickt man auf dem Histogramm von Abb. 5.6 auf dem Balken für die Altersgruppe 35, erhält man
ein Histogramm ähnlich des Histogramms von Abb. 5.7.
Darstellung des Zusammenhangs zwischen quantitativen und qualitativen Daten (z.B. zwischen Alter und Geschlecht):
Die Funktionalitäten sind dieselben wie in Punkt 4. Für jede Klasse auf der X-Achse sind die Daten für die Y-Achse als
gestapelte Balken dargestellt. Die Drill-Down-Funktionalität wird nicht unterstützt, weil abhängend
davon auf welchem gestapelten Balken geklickt wird, gelangt der Benutzer in verschiedene Histogramme für die selbe Klasse,
was nicht gewünscht ist. Der Benutzer kann wieder
die Balkenanzahl und die Skalierungsparameter für die X-Achse eingeben. Diese Aufgaben sind von den
Komponenten histogramm_prozent.cfc und histogramm_skal_prozent.cfc erfüllt (Abbildung 5.8).
Abbildung 5.8:
Zusammenhang zwischen quantitativen und qualitativen Daten (zwischen Alter und Geschlecht)
Darstellung des Zusammenhangs zwischen quantitativen und booleschen Daten (z.B. zwischen Alter und Enhancement):
Wie in Punkt 5 und 3. Das zweite Datenbankattribut ist eine 0/1 Variable. Die Variabilität in den Messungen wird
auch berechnet und dargestellt. Zuständige Komponenten sind histogramm_prozent_0_1.cfc
und histogramm_ skal_prozent_0_1.cfc (Abbildung 5.9).
Abbildung 5.9:
Zusammenhang zwischen quantitativen und booleschen Daten (zwischen Alter und Enhancement)
Die graphische Benutzeroberfläche sollte möglichst leicht bedienbar sein. Der Benutzer bekommt
auf einen Blick alle verfügbaren Attribute von der Datenbank und er kann auswählen, welche Daten visualisiert
werden müssen. Er kann Variablen nur für die X-Achse auswählen, für die beiden Achsen und er
kann auch einen Selektor auswählen, ob alle Beobachtungen, die ersten Beobachtungen für diese Variable
oder die letzten Beobachtungen angezeigt werden sollen. Als Voreinstellung werden die ersten Beobachtungen dargestellt. Wenn der
Benutzer seine Wahl getroffen hat und dann den Button "´Histogramm anzeigen"´ anklickt, werden die Daten
in Form eines Histogramms dargestellt (siehe Abb. 5.10).
Abbildung 5.10:
Die Benutzerschnittstelle
Bei quantitativen Daten für die X-Achse stehen mehrere Funktionalitäten zur Verfügung (siehe Abb. 5.11):
Anzahl der Balken verändern: Der Benutzer kann die gewünschte Anzahl der Balken angeben und dann
mit dem "´Submit"´ Button bestätigen. Die maximal erlaubte Balkenanzahl ist vorgegeben.
Mit den "´+"´ und "´-"´ Tasten kann der Benutzer die Balkenanzahl entweder erhöhen oder mindern.
Von:... Bis:... Schrittweite:...: Es ist möglich, dass nur einen Teilbereich der X-Skala
angezeigt wird. Der Benutzer muss den gewünschten Startwert, Endwert und die Schrittweite angeben und dann mit dem
"´Submit"´ Button bestätigen.
Drill-Down-Funktionalität: Über die Drill-Down-Funktionalität - d.h. per linken
Mausklick auf den zu betrachtenden Balken - gelangt man zum Histogramm der ausgewählten Gruppe.
Abbildung 5.11:
Beispiel für den Zusammenhang zwischen quantitativen und qualitativen Daten
Mit diesem Praktikum wurde eine Bibliothek für Datenvorverarbeitung und Datenvisualisierung entwickelt. Die Komponenten der Bibliothek
verbessern die eingebauten graphischen Funktionen von ColdFusion MX bei der Darstellung statistischer Daten,
indem sie die Daten intelligent vorbereiten, analysieren und dann in einer statistisch adäquaten Form ausgeben.
Hierbei wurde auch eine graphische Benutzeroberfläche entworfen, um eine schnelle Auswahl und Darstellung der Daten zu ermöglichen.
Nach dem Abschluß des Fortgeschrittenen-Praktikums werden die Ergebnisse der Datenvisualisierung mit gängiger
statistischer Software geprüft und validiert und dem Sylvia Lawry Centre zur Verfügung gestellt.
Ziel des Fortgeschrittenen-Praktikums war auch die Vorbereitung der Daten und ihre Visualisierung in Form eines Scatter-Plots.
Dabei sollten auch das Konfidenzintervall und die Regressionsgerade berechnet und dargestellt werden.
Der Teil, der die Daten für die Visualisierung mit ColdFusion
aufbereitet, das Konfidenzintervall und die Regressionsgerade berechnet, ist implementiert worden. Es hat sich aber herausgestellt, dass
man mit den graphischen Funktionen von ColdFusion zwar einen Scatter-Plot darstellen kann, aber wenn das
Konfidenzintervall und die Regressionsgerade dazu gezeichnet werden, wird das ganze Bild nicht sehr sauber. Besonders bei vielen
Daten sind die Geraden zu unregelmäßig (siehe Abb. 6.1) und das Programm wird sehr langsam.
Abbildung 6.1:
Scatter-Plot mit Konfidenzintervall und Regressionsgerade
Eine weitere gewünschte Erweiterung der Bibliothek wäre die Implementierung einer Komponente, die bei qualitativen Daten für jedes
Merkmal ein getrenntes Bild zeichnet und diese Bilder auf einer Seite darstellt, damit die verschiedene Merkmale leicht vergleichbar sind.
![\includegraphics[width=5cm]{siegel.eps}](img2.png)


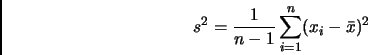
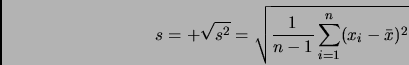
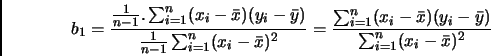
![\includegraphics[height=18cm]{block_dia_bibl.eps}](img57.png)
![\includegraphics[width=12cm]{act_dia.eps}](img58.png)
![\includegraphics[width=8cm]{gender.eps}](img59.png)
![\includegraphics[width=8cm]{course_gender.eps}](img60.png)
![\includegraphics[width=8cm]{gender_enh.eps}](img61.png)
![\includegraphics[width=8cm]{age_first_visit.eps}](img62.png)
![\includegraphics[width=8cm]{age_first_visit_skal.eps}](img63.png)
![\includegraphics[width=10cm]{age_first_visit_gender.eps}](img64.png)
![\includegraphics[width=10cm]{age_onset_enh.eps}](img65.png)
![\includegraphics[width=15cm]{index.eps}](img66.png)
![\includegraphics[width=14cm]{age_course.eps}](img67.png)
![\includegraphics[width=12cm]{scatter2.eps}](img68.png)